依賴反轉原則 DIP
夾心餅乾原則!?
此篇文章偏重於以圖解方式,簡單帶大家了解 依賴反轉原則 哦,有興趣就往下看吧!
DIP 為 Dependency Inversion Principle 簡寫,均意為依賴反轉原則。
👍 開發途中若有遵循此原則將有助於將軟體模組之間做解耦動作!
❓ 為何軟體模組之間需要解耦,回頭再來告訴各位。
定義
以下擷取自 wikipedia
- High-level modules should not depend on low-level modules. Both should depend on abstractions (e.g. interfaces).
- Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
1️⃣ 高層次模組不應該直接依賴低層次模組,它們都應該依賴抽象層!
2️⃣ 抽象層不應該受到低層次模組影響而改變,反而是低層次模組要去依賴抽象層!
見解
老實說當初在看 DIP 原則,我根本看不懂定義在寫什麼東西 (´_ゝ`) ···
寫了約有 1 ~ 2 年程式後,才漸漸明白 DIP 原則想要傳達的意涵 (┐「ε:)
通常一個系統變化最頻繁的地方就是商業邏輯,可能因客戶的需求變動時常有變化,所以我們可以將商業邏輯視為是比較高層次的(意為商業邏輯都會寫在比較高層次模組的位置)。
換句話說,通常變化不大的計算邏輯或功能型程式,我們都會實作在比較低層次模組的位置哦!
當我們理解高低層次模組概況後,那它們之間如何互動?就是我們這次探討的 DIP 原則囉!
其實可以將定義比喻為夾心餅乾,蛤?Σ(°Д°;
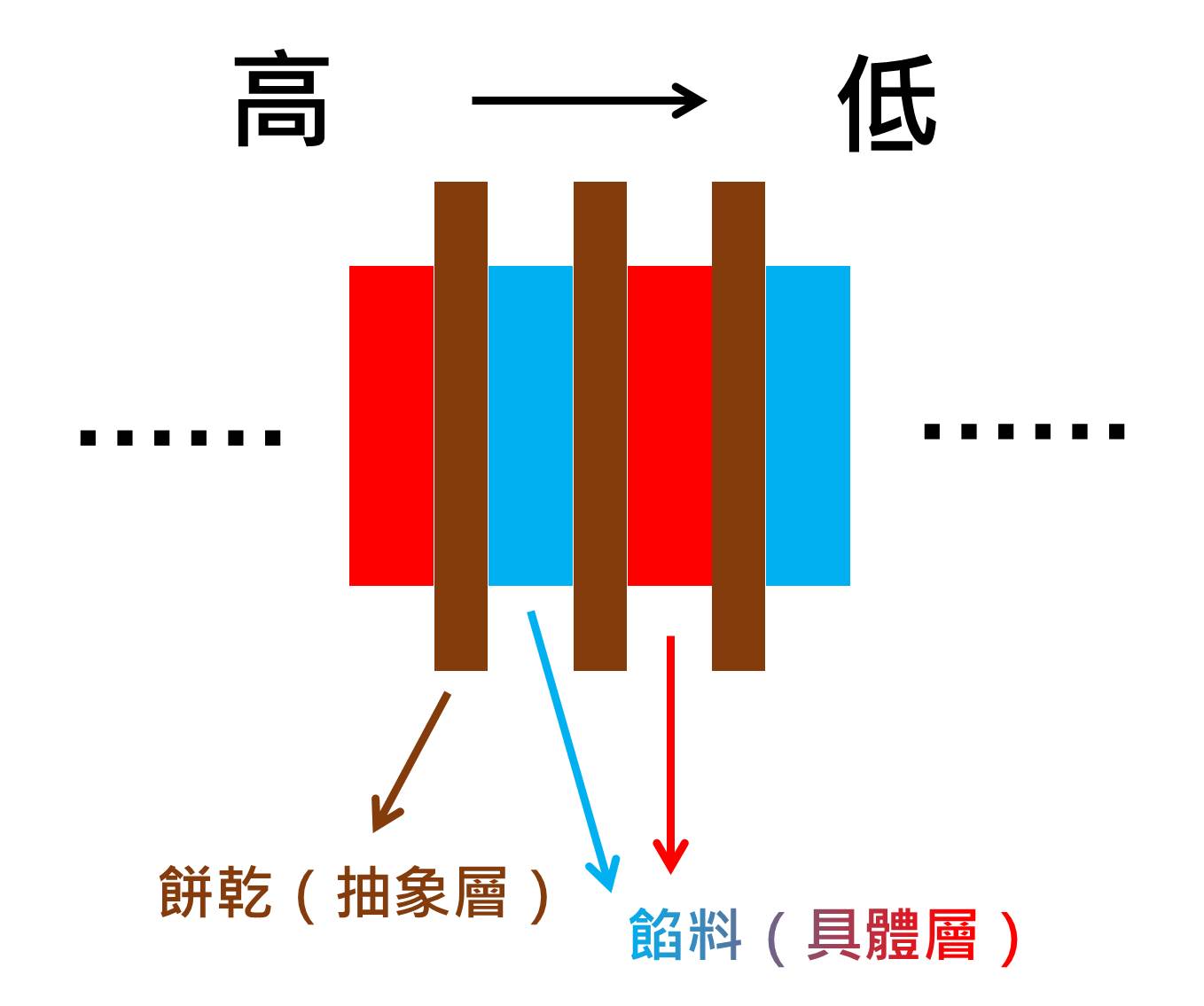
因為有餅乾(抽象層)的關係,兩種餡料(具體層)並不會實際碰到彼此,換句話說,這兩餡料可以各自加上一些佐料(實作各自發展),但倘若兩餡料需要做到保持各自風味的前提下做結合,就需要餅乾來幫忙!
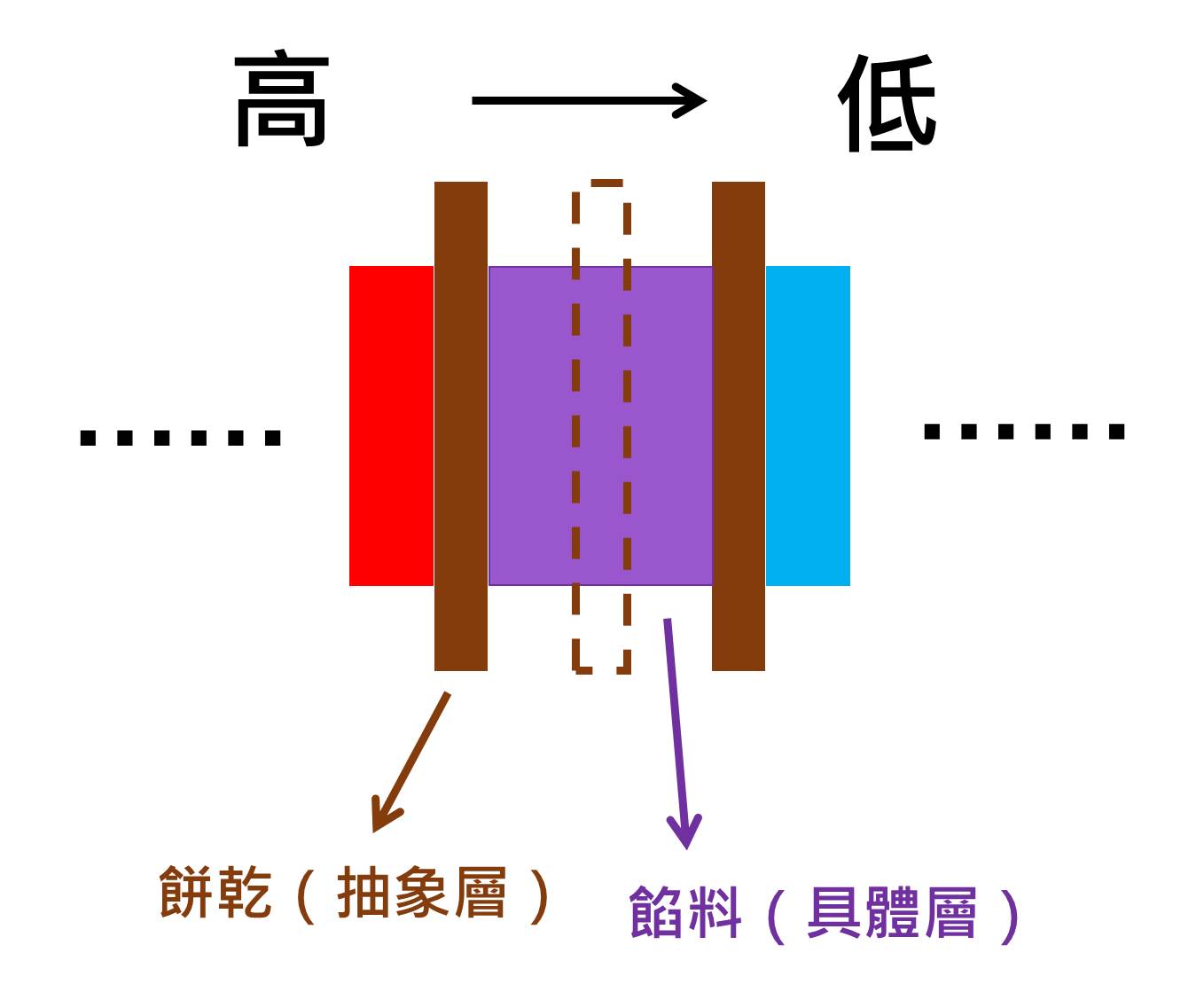
倘若沒有餅乾的保護,兩種餡料就會混合在一起(程式有相依性,即為程式耦合),如上圖。
類別圖探討
底下就從類別圖來看 DIP 原則吧!
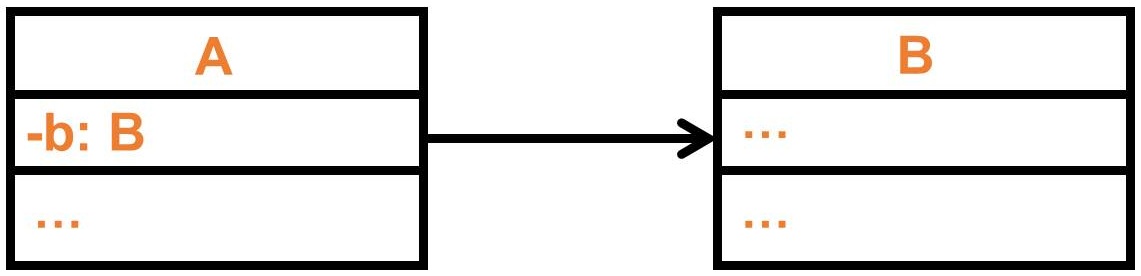
這是一個典型的 A 依賴 B 的類別圖,有幾點可以討論:
- A 如果沒有 B 的話,A 的功能很大機會受到 B 的牽制
- 當 B 的異動很大時,A 的功能保險起見都應該要重新測試,嚴重的話甚至改 B 連帶需要改 A
相信大家對於這兩點都是不樂見的,這邊還只是拿出類別之間的相依關係討論而已,更進階的層次還有元件之間的相依性,但不論是類別還是元件,其實都可以套用 DIP 的相似概念來達到解耦目的!
接著當我們將上圖套用 DIP 原則之後,會變成怎麼樣呢?
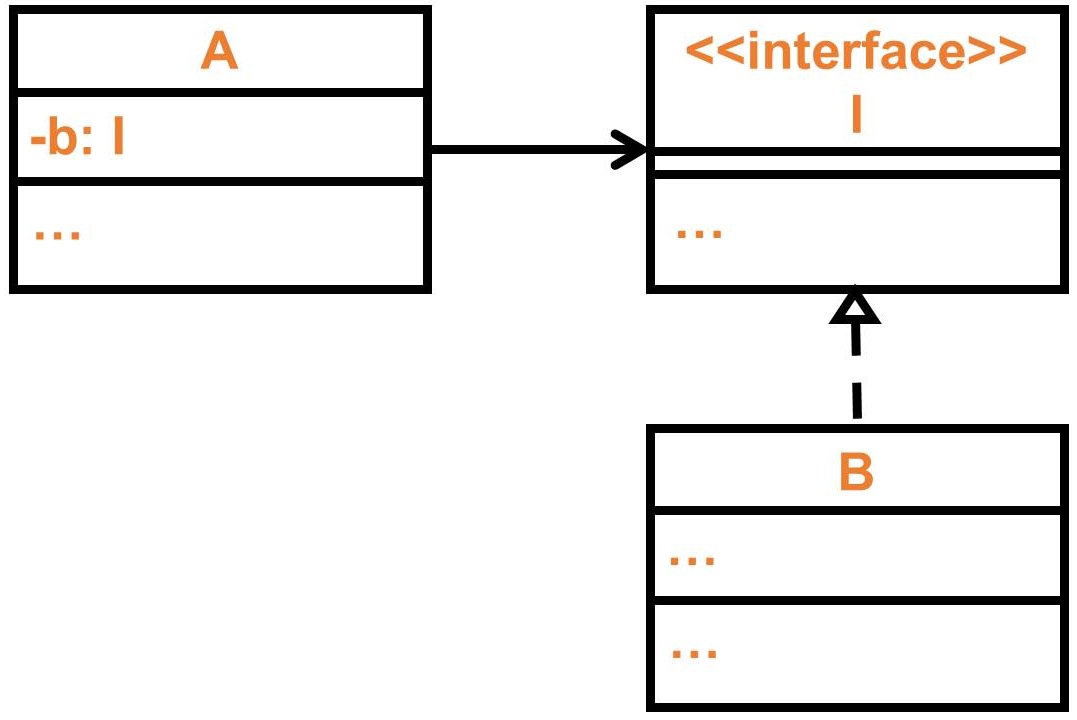
這是一個典型的 A 依賴 I 的類別圖,有幾點可以討論:
- A 不一定要 B,只要是實作於 I 的都可以接受
- 即使 B 的異動很大,以 A 的角度來看只要給我符合的結果就行,我不管你 B 如何去實作
主觀來看 A(高層次模組)要能正常運作,一定會需要 B(低層次模組)的協助,而 DIP 將這樣的關係倒反過來,實際上當然不是 B 跑去依賴 A,而是 A 和 B 都去依賴 I(看似 A 依賴 B,但不是那麼明確罷了)。
延伸
但倘若我們以 A 依賴 I 為例子來看, 其實還有一個問題未解··· Σ(;゚д゚)
那究竟誰要產生去 B 呢?還是 A 嗎?那這樣有解決根本問題嗎?
接著我們來談談工廠模式是如何解決產生 B 的問題。
工廠模式
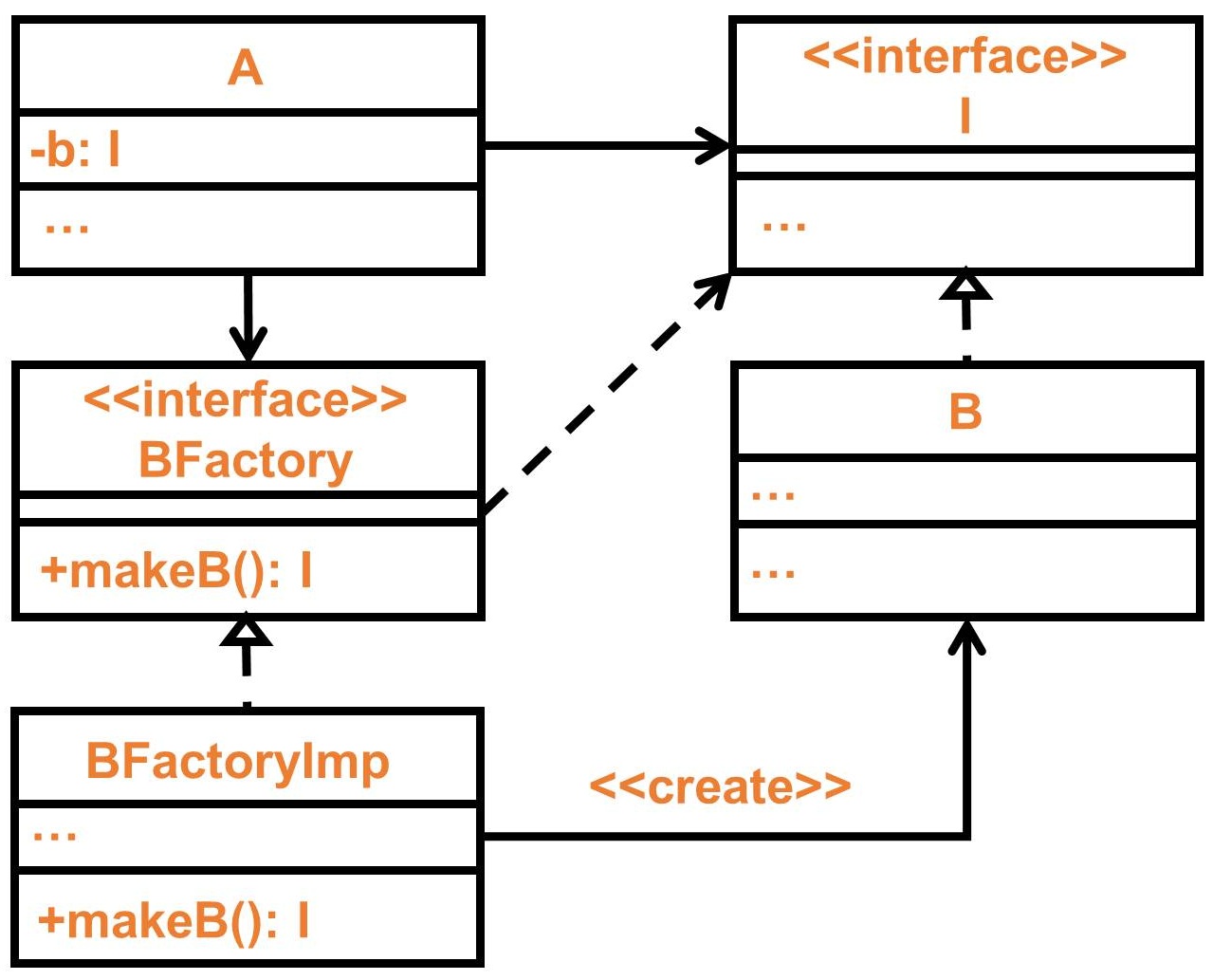
從上面類別圖可以很清楚知道誰去產生了 B,A 透過工廠(Factory)取得了 B,而 A 依賴 BFactory 介面這也意謂著,實際具體工廠也不一定要 BFactoryImp,只要實作 BFactory 介面的具體工廠都可以接受。
若以 A 的角度來看,它只會知道我得到了一個 B,是由工廠幫它產生出 B!
疑點
眼尖的話你會發現···
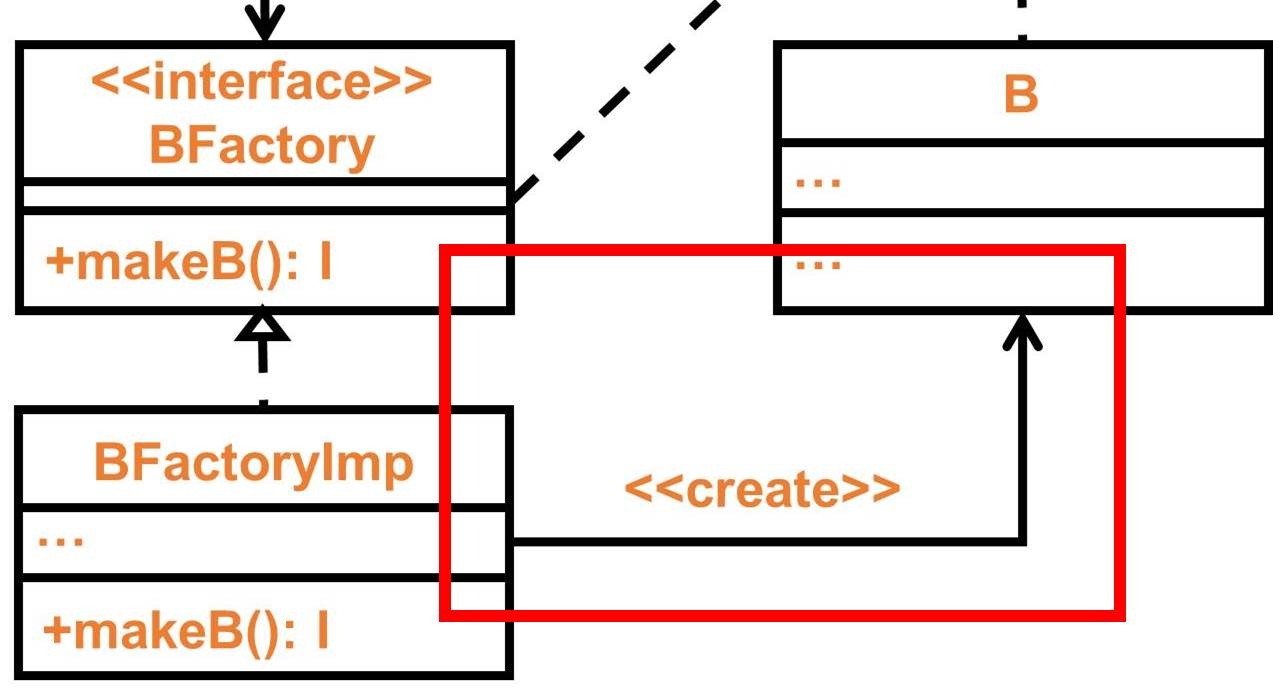
BFactoryImp 因為依賴 B,所以違反了 DIP 原則,你可能會想這不是廢話嗎?
因為 BFactoryImp 目的就是要產生 B 阿,這要怎麼避免?
這其實印證了要在一個系統上完全遵守 DIP 原則幾乎是不可能的事情,所以工程師必須要思考如何拿捏,而不是一味地去遵循原則哦!
為什麼需要解耦?
你應該也不會希望測試一模組,還要連帶測試其它模組(更何況這不是你團隊開發的模組),解耦目的終究是希望讓軟體模組各自可以彈性發展而不互相影響,其實這也會間接影響團隊職責切割,很有趣吧!
舉個例子來說,可以試想看看商業邏輯跟儲存資料方式這兩塊,將計算的職責交給商業邏輯,而實際資料儲存則交給儲存資料方式。
- 處理商業邏輯的工程師,只需要思考如何因應需求變化而改變其商業邏輯程式
- 處理儲存資料方式的工程師,則只需要思考如何將接到手的資料確實儲存起來
好處
- 避免掉多數直接改 A 壞 B 的情況
- 職責逐漸單一化,可以寫出更有價值的單元測試(程式耦合嚴重,幾乎是寫不出單元測試,要注意!
- 可達到快速除錯的目的,因職責已逐漸單一化
- 從元件角度來看,可以分開部署,不需要重新編譯整個專案(不過端看專案本身如何去切層
- 程式會愈來愈符合物件導向設計原則(很神奇吧~
- 有想到在回來補充 XD···
參考
💭 亂談軟體設計(5):Dependency-Inversion Principle
結尾
希望這篇文章可以讓大家了解 Dependency Inversion Principle,若在開發時就盡可能遵循該原則,對未來的幫助絕對不會少,它就是短期看不出什麼效果,但長期來看你會後悔為什麼當初不做 (´_ゝ`)···
贊助支持
如果你喜歡我們的文章,或是這些內容對你有幫助,歡迎透過以下平台請我們喝杯咖啡,支持我們持續創作!

